자체 감독(Self-supervised) 프레임워크 'AV-HuBERT' 소개
음성·입술 움직임 동시에 훈련하는 최초 언어모델 시스템
연구진 "스마트폰·AR 안경에 탑재하면 효과 극대화"
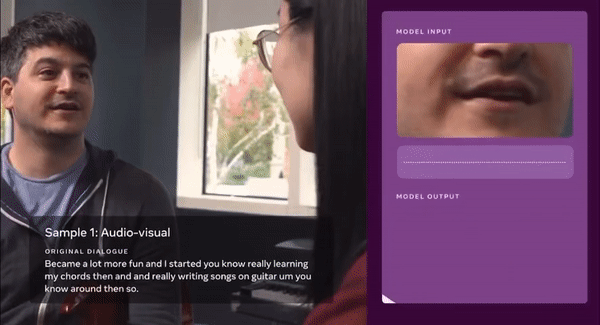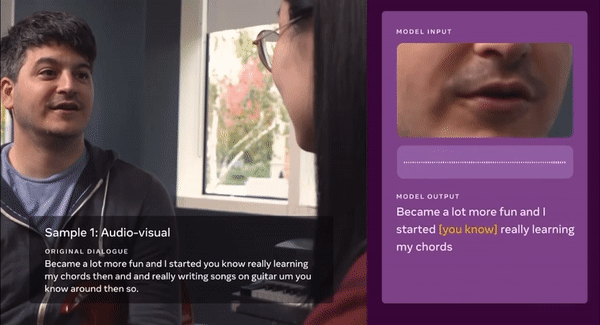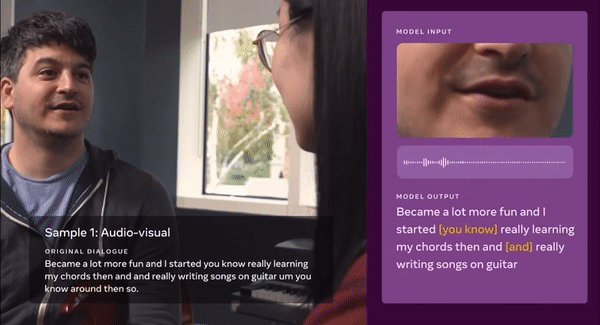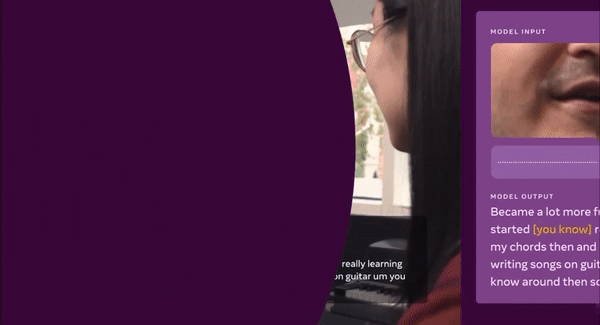
사람 말을 기존 언어모델보다 더 정확히 이해하는 시스템이 나왔다. 입술 움직임과 음성 데이터로 학습해 여러 명이 동시에 말하거나 인파로 붐빌 때도 사용자 말만 정확히 잡아 알아듣는다. 이 기술을 스마트폰이나 증강현실(AR) 안경에 탑재하면 더 똑똑한 '인공지능(AI) 비서'가 탄생할 전망이다.
메타플랫폼(이하 메타, 구 페이스북)이 7일 시청각 데이터로 훈련해 사람 말을 더 정확히 이해하는 최첨단 자체 감독(Self-supervised) 프레임워크 'AV-Visual Hidden Unit BERT(AV-HuBERT)'를 소개했다. 라벨링 하지 않은 비디오 데이터에서 음성·입술 움직임을 동시에 사용해 훈련하는 최초 언어모델 시스템이다. 인간이 사용자 말을 이해할 수 있는 수준이다.
메타 연구진은 "해당 모델은 공개적으로 사용할 수 있는 'LRS3(Lip Reading Sentences 3)'과 '복스첼렙(VoxCeleb)' 데이터 세트로 훈련했다"고 말했다. LRS3은 테드(TED)와 테드엑스(TEDx) 강연에서 수집한 음성을 모아둔 데이터 셋이다. 복스첼렙은 언어 시청각 대규모 데이터다. 이를 통해 사람이 말할 때 내는 목소리와 입술 움직임 조합을 통해 언어를 인식할 수 있다.
적은 데이터로 기존 모델보다 높은 정확도, 낮은 오류율
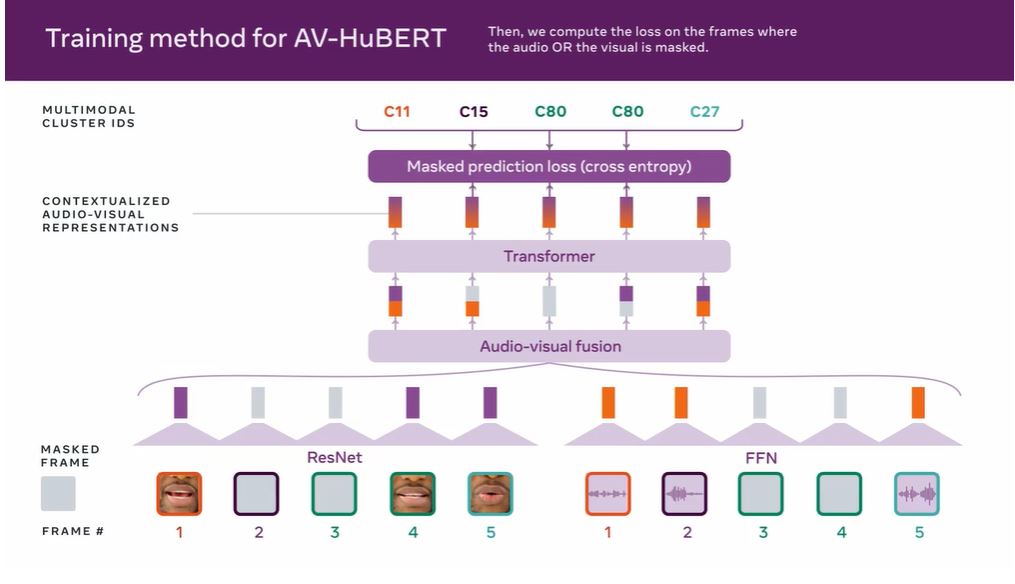
AV-Hubert는 현재 기존 음성 인식 시스템보다 75% 더 정확하다. 기존 레이블 1/10 데이터 양만 사용해도 기존 시스템을 훨씬 능가한다. 이 기술이 스마트폰이나 증강현실(AR)안경에 탑재된 AI 비서에 적용하면 우리가 무엇을 말하고 있는지 더 정확히 이해할 수 있다.
연구진은 ▲말소리와 배경 소음이 동일한 경우 ▲말소리가 다른 사람들 목소리와 섞인 시나리오를 만들어 기존 모델 'AV-ASR'과 AV-HuBERT 기능을 비교했다.
말소리와 배경 소음이 똑같이 클 때, 기존 모델 AV-ASR은 25.5%의 오류율을 기록했다. 동일한 조건에서 AV-HuBERT는 3.2%를 보였다.
말소리가 다른 목소리와 섞인 경우, AV-Hubert 모델은 자신에게 명령하는 사람을 빨리 포착하고 그에 집중했다. 언어오류율(WER)은 2.9%을 기록했다. 기존 모델은 오류율 37.3%을 보였다.
시청각 정보가 결합한 AV-HuBERT는 훨씬 적은 양의 비디오 데이터로도 기존 모델보다 효율성이 높다. 메타 연구진은 “세계 대부분 언어에서는 라벨링 된 빅데이터를 얻기 어렵기 때문에, 적은 양으로 더 많은 언어와 더 많은 응용 분야에서 소음 방지 자동음성인식(ASR) 시스템을 구축하는 데 도움 될 것이다”고 설명했다.
연구진은 "이 기술이 스마트폰이나 AR 안경에 탑재된 AI 비서에 적용하면 우리가 무엇을 말하고 있는지 기존보다 더 정확히 이해할 수 있다"고도 말했다. 예를 들어, 클럽이나 공항 같은 소음이 큰 장소에서도 사용자가 명령을 내리면 AI 비서가 명확히 알아들을 수 있다.
AI타임스 김미정 기자 kimj7521@aitimes.com
Copyright © '인공지능 전문미디어' AI타임스 (http://www.aitimes.com/)
무단전재 및 재배포 금지
"더 똑똑한 'AI 비서' 온다"...메타, 사람 말 더 정확히 듣는 언어모델 소개 - AI타임스
사람 말을 기존 언어모델보다 더 정확히 이해하는 시스템이 나왔다. 입술 움직임과 음성 데이터로 학습해 여러 명이 동시에 말하거나 인파로 붐빌 때도 사용자 말만 정확히 잡아 알아듣는다. 이
www.aitimes.com
'AI테크' 카테고리의 다른 글
| 한국전자통신연구원, 초정밀·고효율 기술로 지난해 큰 성과 (1) | 2022.01.13 |
|---|---|
| AI와 IoT 융합한 지능형 사물인터넷, 초지능 시대 연다 (0) | 2022.01.11 |
| [위드AI] ⑬ 인공지능이 미래 의료 바꿀까 (0) | 2022.01.03 |
| "사람 형체 정확히 골라 생명 불어넣어"...메타, 아동용 애니메이션 SW 소개 (0) | 2021.12.30 |
| [CES 2022] "韓 AI 기술력 알린다"…솔트룩스·나무기술·세이프웨어, 출격 채비 (0) | 2021.12.29 |