추론은 기존 데이터셋 취합으로 하기 어려운 단계
'엔드-투-엔드' 방식인 기존 지도학습에서 벗어나야
PLC 러닝 기반으로 한 '로버스트 로직(Robust Logic)' 이론 소개
추론 메커니즘으로 AI 추론 효율성 높여

"아리스토텔레스는 땅콩을 좋아했을까?" 레슬리 밸리언트(Leslie Valiant) 미국 하버드대 교수가 2일 열린 '삼성 AI 포럼 2021' 기조연설에서 던진 질문이다.
이 질문에 답하기 위해선 아리스토텔레스를 연구해야 한다. 그가 언제 어디서 살았는지 알아야 하고, 아리스토텔레스가 거주한 곳에서는 땅콩을 구할 수 있었는지 등도 조사해야 한다. 이러한 연구를 통해 취합된 정보로 아리스토텔레스가 땅콩을 좋아했는지 답할 수 있다.
이 답을 구하기 위해 사용한 방법은 추론이다. '아리스토텔레스가 좋아하는 음식'이라는 데이터셋으로 학습한 것이 아니다.
인공지능(AI)은 사용되는 영역이 넓어지면서 새로운 요구사항을 받고 있다. 대표 사례가 AI 추론을 통한 예측이다. 밸리언트 교수는 삼성 AI 포럼 2021 기조연설자로 나서 이 문제를 해결하기 위해선 "표준화된 지도학습을 뛰어넘은 접근방식이 필요하다"고 말했다. 그는 AI 추론 모델을 위해선 지도학습 영역 확장이 필요하다고 설명했다. 또 현재 자신이 연구 중인 '로버스트 로직(Robust Logic)'이 확장의 답이 될 수 있다고 밝혔다.
◆ 로버스트 로직, 추론 메커니즘으로 AI 기능 확장
밸리언트 교수는 로버스트 로직에 대해 "AI 기능을 확장하는 이론"이라고 정의했다. 또 "기능성이 확장되면 AI는 머신러닝에 더해 추론을 할 수 있는 능력도 갖추게 된다"고 설명했다.
로버스트 로직을 쉽게 설명하면 내부에 여러 개의 상자를 가진 학습도구로 정의할 수 있다. 기존 표준화된 지도학습은 한 개의 상자만 있었다. 입력값을 상자에 넣으면 하나의 상자를 통해 출력값이 나오게 된다. 그만큼 사용자는 넣은 입력값을 토대로 출력값을 예상할 수 있다. 감자를 튀김기기에 넣으면 튀긴 감자가 되는 것을 알 수 있는 것과 유사하다.
로버스트 로직은 기존 지도학습과 다르다. 여러 개의 상자가 존재한다. 사용자가 입력값을 넣었지만 출력값은 예상할 수 없다. 감자를 큰 기기에 넣었는데 그 기기 내에는 튀김기기, 찜기, 과자를 만드는 기기 등 여러 기기가 있다고 생각하면 된다. 사용자가 기기에 감자를 넣었지만, 이 감자가 튀긴 감자가 될지, 감자 칩이 될지, 삶은 감자가 될지 알 수 없다. 튀기고 삶아져 과자가 된 감자가 나올 확률도 있어 사용자는 출력값을 예상하기가 더 어렵다.
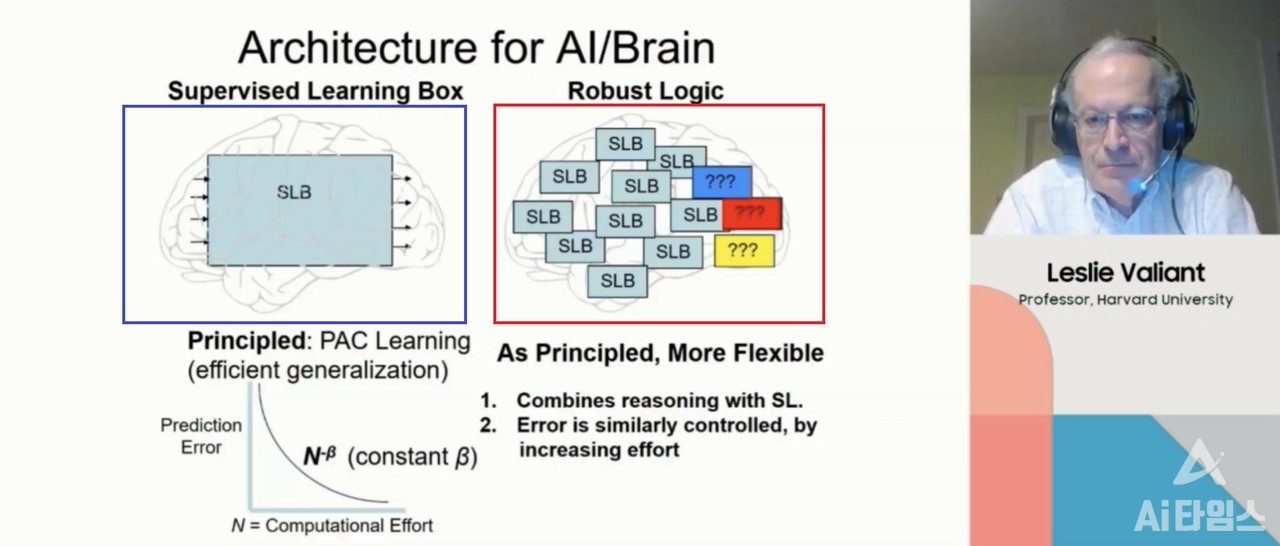
밸리언트 교수는 "표준화된 지도학습은 하나의 상자만 가지고 학습을 시키지만, 로버스트 로직은 여러 개의 상자를 가지고 있고 상자는 더 추가될 수 있다"며 "표준 머신러닝은 입력값을 넣으면 엔드-투-엔드(End-to-end) 방식으로 출력값이 나오지만, 로버스트 로직은 출력값이 다른 박스의 입력값이 될 수 있어 더 복잡한 방식을 갖는다"고 설명했다. 이어 "로버스트 로직 방식에는 추론 메커니즘이 존재한다"면서 "여러 박스에서 도출된 예상값이 연결고리로 묶여 더 강한 기능을 낼 수 있다"고 부연했다.
◆ PAC 러닝 기초, 연산 많아질수록 가치 있는 결과 나와
로버스트 로직의 유용성은 지도학습 모델 중 하나인 PAC 러닝에서 나타난다. PAC 러닝은 밸리언트 교수가 창시한 머신러닝 기초가 된 지도학습 모델이다. '아마도 대략적으로 정확한 학습'을 의미한다. 학습하고자 하는 임의의 모델을 주어진 정확도 α로 학습하는 것이 목표일 때, 주어진 확률(50%보다 많은)로만 정확도 α를 달성한다면 성공한 것으로 간주하는 개념이다.
그는 "PAC 러닝은 효율적인 일반화 구현의 원칙적인 정의"라고 말했다. 이어 "연산 양이 증가하고 더 많은 수의 사례를 활용하면 오류가 발생한 확률은 줄어들게 된다"며 "개발자가 정확한 예측을 위해 더 많은 연산을 하고자 노력한다면 그만큼 가치 있는 결과가 도출하게 된다"고 설명했다.
로버스트 로직은 내부에 많은 상자가 있어 많은 연산이 이뤄지므로 기존 지도학습보다 빠르고 쉽게 가치 있는 결과를 도출해낼 수 있다는 것.
밸리언트 교수는 "로버스트 로직은 현실과 비슷한 일반화를 구현해낼 수 있고, 여기에 더해 지도학습 박스에서 도출해낸 결과들을 바탕으로 추론을 할 수 있다"면서 "여기에 더 많은 연산이 수행된다면 오류도 통제할 수 있다"고 밝혔다.

◆ 표준화된 지도학습이 가진 추론 한계 극복 가능
로버스트 로직은 표준화된 지도학습이 가지고 있던 추론의 한계를 극복할 수 있을 것으로 전망된다.
표준화된 지도학습으로 코끼리 그림을 분류하는 과제를 수행한다고 하면, 개발자는 보통 코끼리 그림을 AI에 학습시킨다. 인터넷에 있는 모든 그림을 학습시킨다면 AI는 엔드-투-엔드 방식으로 높은 정확도의 출력값을 낼 수 있다.
하지만 현재 AI는 코끼리 그림 분류가 아닌 더 복잡한 인지 과제를 분류해야 하는 과제를 안게 됐다. 현실에서 이뤄지는 수많은 인지는 사용자 경험으로 이뤄진다. 사람들은 의사소통을 통해 예측하고 결괏값을 내는 것이 가능하다. 하지만 AI는 그 과정이 어렵다. 여기서 엔드-투-엔드 방식인 기존 지도학습의 한계가 드러난다.
스포츠 뉴스 단어 맞추기 게임에 비유하면 보다 이해가 쉽다. 한국에 있는 A팀에서 활약하던 한 선수가 유럽 B팀으로 이적한다고 했을 때, 해당 기사에 '유럽 B팀' 단어가 빠졌다고 가정해보자. 기존 지도학습 방식에서는 다른 기사에 나온 데이터를 취합해 답을 찾을 수 있다.
그런데 뉴스가 보도되기 전 빠진 단어를 예측해야 했다면 어떨까. 기존 정보가 없기 때문에 답을 얻기 위해선 기존 지식을 사용해야 하고, 한 번도 모아지지 않은 지식도 모아야 한다. 추론이 필요한 것. 밸리언트 교수는 이 추론 방식을 엔드-투-엔드를 넘어 많은 상자가 있는 로버스트 로직으로 해결할 수 있다고 설명했다.
그는 "사실 PAC 러닝도 로버스트 로직도 새로운 것은 아니다"라며 "새로운 것이 있다면 효율적인 실현과 실제 적용을 뒷받침해야 하는 이론 예측이라는 영역이다"라고 말했다. 이어 "이 영역은 AI와 밀접한 연관이 있지만, 아직 활용되지 않았다"면서 "기존에 실현되지 않은 방향으로 AI를 작동시킬 수 있기 때문에 이 이론은 AI 산업에 새로운 기회가 될 것"이라고 강조했다.
AI타임스 김동원 기자 goodtuna@aitimes.com
Copyright © '인공지능 전문미디어' AI타임스 (http://www.aitimes.com/)
무단전재 및 재배포 금지
[삼성 AI 포럼 2021] 레슬리 밸리언트 하버드대 교수 "AI 추론 위해선 표준화된 지도학습 넘은 새로
\"아리스토텔레스는 땅콩을 좋아했을까?\" 레슬리 밸리언트(Leslie Valiant) 미국 하버드대 교수가 2일 열린 \'삼성 AI 포럼 2021\' 기조연설에서 던진 질문이다. 이 질문에 답하기 위해선 아리스토텔...
www.aitimes.com
'AI테크' 카테고리의 다른 글
| 페이스북, 안면 인식 기능 폐지한다...얼굴 스캔 데이터도 삭제 (0) | 2021.11.03 |
|---|---|
| [삼성 AI 포럼 2021] 막스 웰링, “분자 검색 엔진 개발하면 시뮬레이션 더 빠르고 정확해져” (0) | 2021.11.03 |
| 맥도날드가 시작한 자동음성주문 ... 나날이 일상 속으로 깊숙이 파고드는 음성 인식 기술 (0) | 2021.11.02 |
| [삼성 AI 포럼 2021] 새로운 소재 개발에 드는 막대한 시간, 이젠 인공지능으로 극복한다 (0) | 2021.11.02 |
| [삼성 AI 포럼 2021]요슈아 벤지오 "초거대 AI 모델에 빠진 것 두 가지, 추론과 경험“ (0) | 2021.11.02 |